自民支持率の時系列比較で「年平均」を利用することで,解釈が変わるほどの影響はないと思うが確認しておこう.下図は松本(2001)の表示<2-3>(p.30)の読売の自民支持率に関して,レンジも追加表示したものである.年平均だけ見せられると,どうしても年間のバラツキが気になるものである.このようにレンジか標準偏差を同時に見せて欲しい.1989年や1993年のレンジは16〜17ポイントもある.消費税と下野の年である.
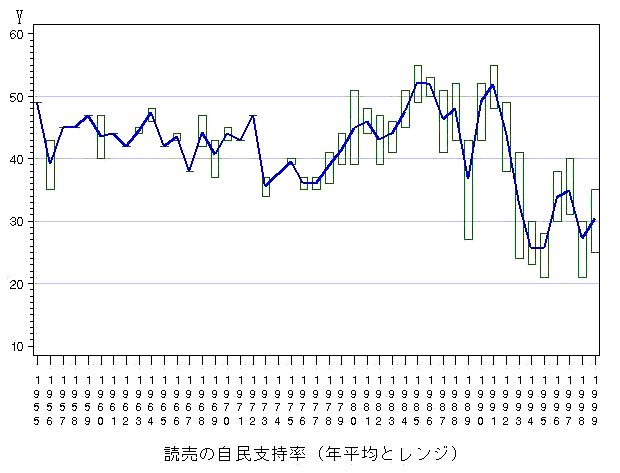
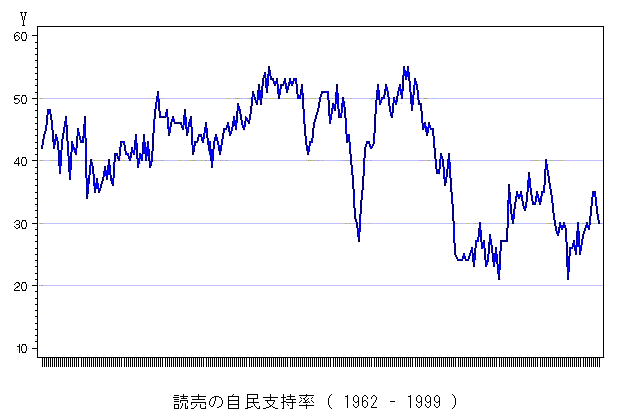
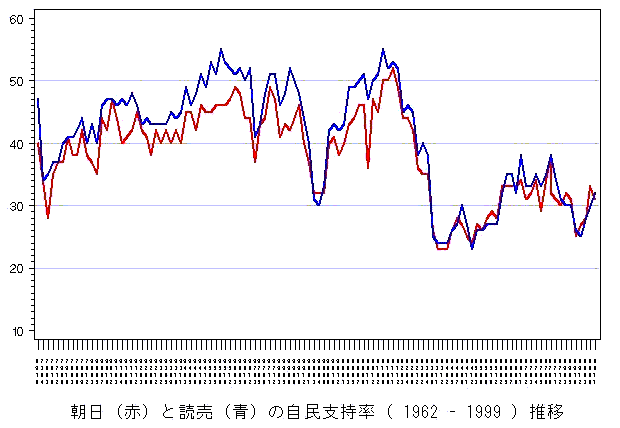
年平均にまとめずに,各回の支持率をそのまま表示した下図を見ると,傾向が激しくなるが,年平均にしたことで,この傾向が見えなくなることはなく,数十年にわたる推移の観察をする限り問題はないようである.
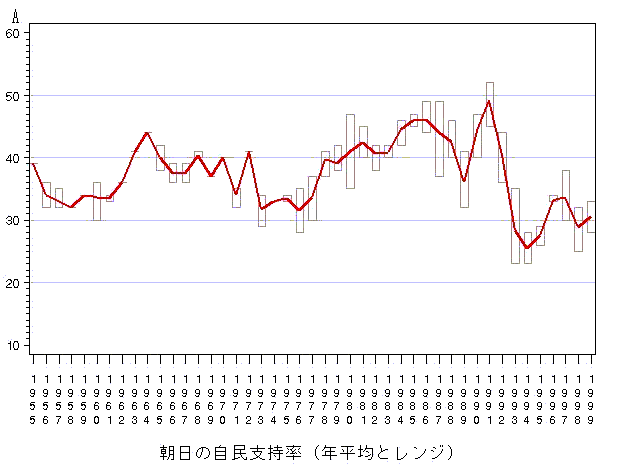
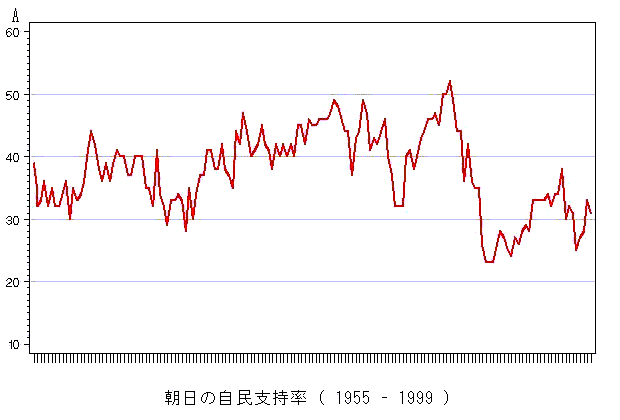
同様に朝日に関しても「年平均」と「生比率」の2つの図を示す.
では,朝日と読売の自民支持率の比較に関してはどうであろうか?.年平均に関する同時プロットは下図のようになる.
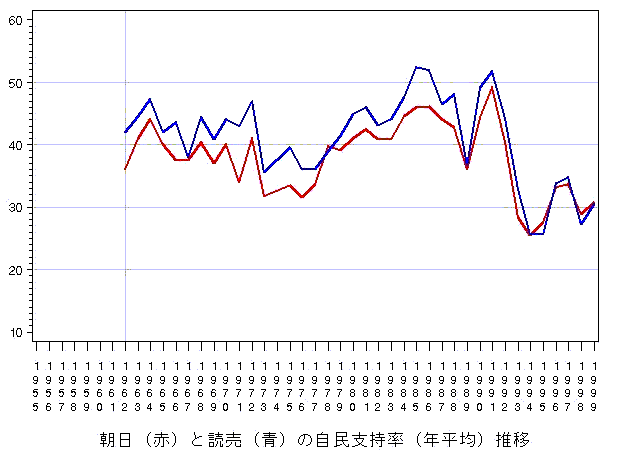
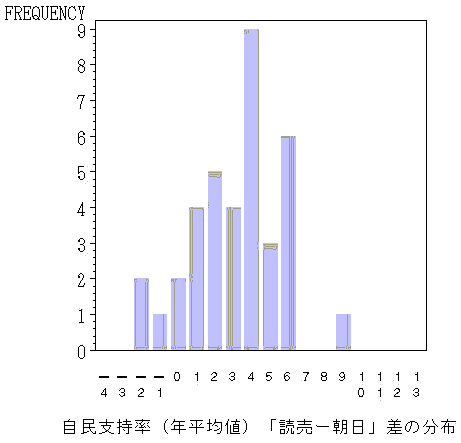
傾向のまとめとして,朝日と読売の自民支持率の差(読売−朝日)の分布を下図のヒストグラムで表示してみよう.0より正の側にかたよっているので,読売に高目になっていることが分かる.下図は年平均のグラフであるが,読売の自民支持率は朝日よりも,平均3.2ポイント高い傾向がある.標準偏差は2.4ポイントである.
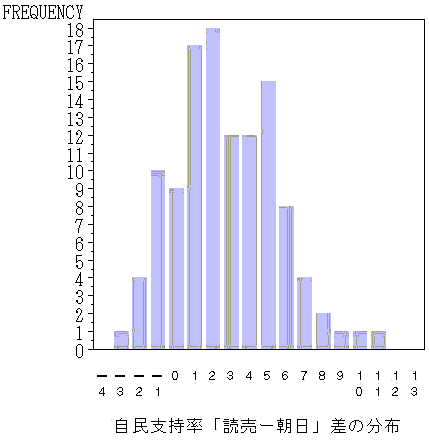
では,生比率はどうであろうか.朝日と読売が同じ月に実施した調査データに関しては,平均2.7ポイントだけ読売が高い.年平均データの3,2ポイントより,やや差が小さい.標準偏差も2.7である.年平均にするとわずかに朝日と読売の差が広がる.もっとも傾向を誤解することはない程度である.
下図は年平均データによる,朝日と読売の自民支持率の散布図である.両社の関係を単回帰分析で確認してみよう.便宜的に読売を説明変数(X)にして,朝日を目的変数(Y)とする.両社には以下の線形構造関係がある.
y = 5.94 + 0.78 x .
決定係数は「0.898」である.残差の平均平方は「1.87」となった.
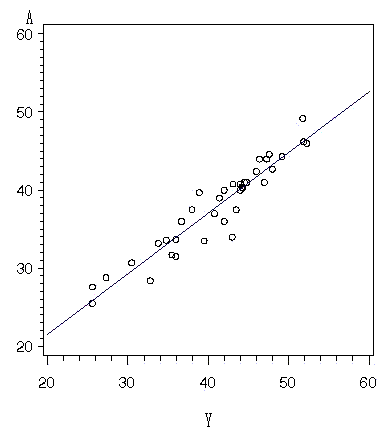
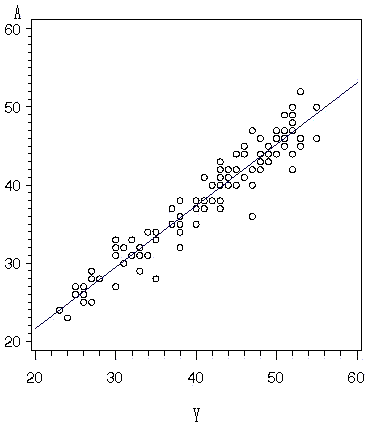
では生比率の比較ではどうであろうか.単回帰分析の結果は,
y = 5.91 + 0.79 X .
となって,年平均の構造とほとんど違わない.決定係数は「0.92」で年平均よりも高いが,平均平方残差は「2.01」となって,わずかに年平均より大きくなる.データが多くて個別事情によるバラツキを年平均よりも多く含むためである.
この結果からも,年平均にすることは大した悪条件とはならないで,結果を解釈することができることが確認できる.
なお,朝日と読売の関係について,さらにダミー変数を導入した重回帰分析モデルを作れば精度が向上することが期待できる.例えば60年代とか70年代というダミー変数である.どこで区切るかは,いつ質的な変化が起きたか,データに反映したかによる.この点に関しては,洞察と解釈の能力に依存する問題である.
もちろん,それは結果的な知見である.本質的に重要なのは,このような時系列データを観察しながら,社会と歴史という背景を考慮し妥当な解釈を導くことである.松本の仕事の良さもそのようなところにある.
調査法に関する解説については指摘しなければならない点がある.「調査データの科学」という節で,世論調査の方法として面接調査と電話調査の2種類を紹介し,さらに電話調査の方法としてユニット法,割当法,RDD法−−の3分類をしている.
この説明に従って分類を図示すると以下のようになる.
┌面接調査
│
└電話調査─┐
│ ユニット法(有権者名簿で抽出し電話番号を調べる)
│ 割当法(電話帳で抽出し有権者を探る)
└ RDD法(名簿を使わずいきなりダイアル)
上記の分類法は実査法と抽出法が混在しており,読者を誤解させる可能性がある.ユニット法と割当法は抽出名簿で区別されるものではない.確率標本か非確率標本かを区別する抽出法の分類である.面接の割当法もあるし,電話帳からの無作為抽出もある.
もし電話調査を分類するのなら,まず抽出台帳として「有権者名簿」「電話帳」「電話番号空間」などに分類され,抽出法として無作為抽出と割当法に分けられる.
RDD法は,抽出台帳として電話番号空間を使う無作為抽出法に相当する.非該当番号として確定するまでは,世帯の可能性を否定せずに追いかけ続けなければいけない.調査実施期間の終了時点になっても接触できなければ,それは「不在票」という未回収票に相当すべき対象である.それがまともなRDD法である.回答を得られる人からどんどん電話しまくって,性・年齢の分布を母集団に似せて割当てる気楽な方法のことではない.
RDD(RDS)は仮想名簿とでもいうような名簿を使う.仮想名簿とはすべての電話番号がもし印刷製本されていれば名簿という形をとる,という意味である.母集団の枠はすべての世帯電話番号空間(枠・リスト)であり,名簿は母集団を部分集合として含む全番号空間である(世帯と固定電話が対応している前提).そこから無作為標本を抽出する方法がRDSという「サンプリング」法である.ただし,その「名簿」には非該当番号(事業所番号,未使用番号)が含まれるので,効率的にそれを除外する抽出方法が研究されてきたのである.
喩えれば,全番号空間という名簿は,住民基本台帳に非世帯(事業所や非居住番地)が混在して編集されている仮想状況である.さらに日本国土のすべての番地区が掲載された「住民・非住民台帳」を仮想してもよい.
冗長性の少ない分類すれば以下のようになる.
実査法─┐
│ 面接法
│ 電話法
│ 留置法
│ 郵送法
└ ・・・・・・
抽出法─┐
│ 無作為抽出法(名簿法,電話番号法,・・・)
│ 属性別割当法(名簿法,電話番号法,・・・)
│ 有作為抽出法(条件選出法・・・)
└ ・・・・・・
抽出元─┐
│ 選挙人名簿
│ 住民基本台帳
│ 住宅地図
│ 電話番号簿
│ 電話番号空間
└ ・・・・・・
蛇足:
ところで「有作為抽出」という用語は一般的でなくここで発明した.一般に有意抽出というのだが有意/有為のどちらを使うべきか迷うところである.意図の有る,作為の有る抽出法のことだが・・・.
以下の日本語の「有意」の意味は異なる.しかもいずれも統計学用語である.
有意抽出 purposive selection
有意水準 level of significance
また「有為」は「有為の青年」の意味であり,有作為ではない.
属性別割当法も一般には割当法というだけである.実際には性別と年齢別を地域別に割当てることが多い.なお,「ユニット法」という用語もたまに聞くことがあるが,小生は寡聞で馴染みが無い.何がユニットなのだろう?
※ p.205 の 64.1.14-15 は誤植か?.
bk1 松本正生氏インタビュー